K8s网络通信原理
K8s网络通信原理
概述
在探索Kubernetes(简称K8s)这一强大的容器编排工具如何管理大规模分布式集群时,理解其内部Pod间的跨节点通信机制至关重要。本节将聚焦于K8s集群内不同节点上的Pod如何实现高效、可靠的互联互通。
场景构建
Kubernetes集群由多台服务器(节点)组成,这些节点在K8s的统一调度与管理下协同工作。每个节点具备运行多个容器的能力,其中可能包含各种业务应用(如Java服务)或基础设施服务(如数据库)。
Kubernetes创新性地引入了Pod这一核心概念,以应对容器间共享网络环境及采用特定设计模式的需求。Pod本质上是一个逻辑上的封装单元,它将一组紧密相关的容器封装在一起,共享相同的网络命名空间、存储卷等资源。比如,一个Java服务及其配套的日志收集系统可以部署在同一Pod中,形成所谓的“sidecar”模式。尽管Pod的设计理念丰富多样,此处我们仅关注其在网络视角下的表现:Pod被视为运行在宿主机上的一个单一网络实体。
同节点Pod间的通信
在单个节点内部,多个Pod间的通信相对直接。Kubernetes通过将Pod接入宿主机上的一个虚拟网桥,巧妙地实现了Pod间的网络连通。网桥作为二层设备,负责处理Pod间的网络数据包交换,确保同节点Pod如同在同一局域网内一般自由通信。
跨节点Pod间的通信挑战与解决方案
然而,当涉及到不同节点上的Pod间通信时,情况变得复杂。这类似于不同Wi-Fi热点下的设备,由于缺乏有效的路由信息,无法直接基于IP地址实现互访。
基础知识回顾
- Pod:共享同一网络命令空间的多个容器。在这里,只要把它理解为一个容器就行。
- Node(节点):K8s集群中的主机。
- 路由表:对于某些ip,应该从哪个设备发送出去,下一条的地址是多少。
- MAC地址:每个硬件设备,全球唯一的标识码。也可以用软件模拟出来。
- ARP表:记录IP地址和MAC地址映射的关系表。
- FDB表:路由器的地址转发表。记录MAC地址和IP地址的的映射关系。
- VXLAN:虚拟扩展局域网,用于子网划分。
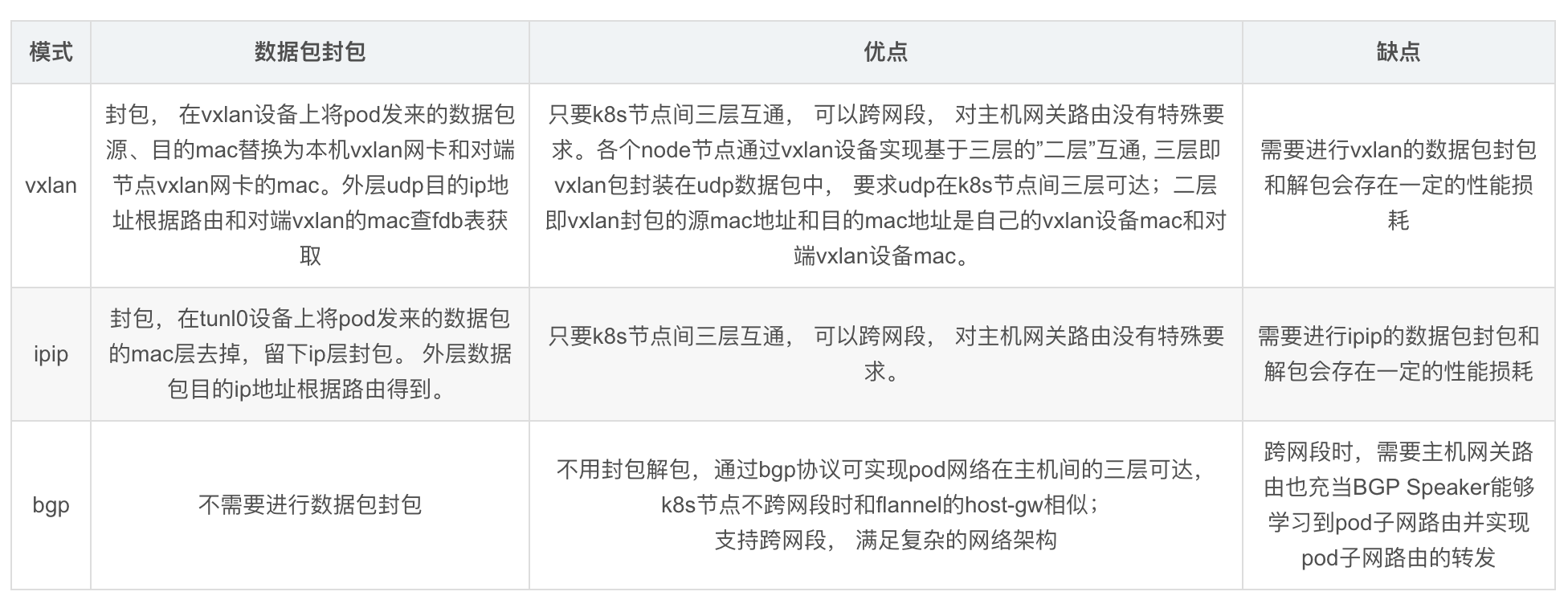
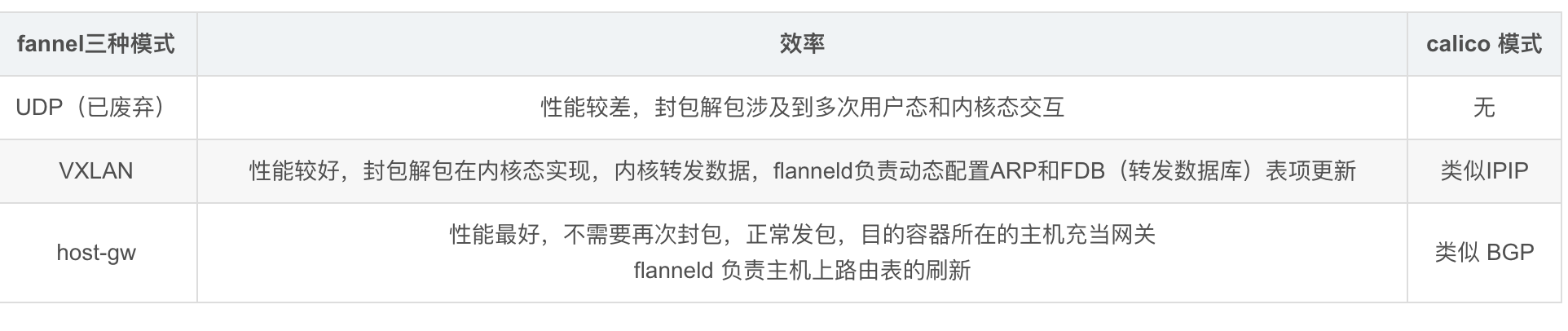
- Flannel:一种K8s的网络插件,用于实现跨节点的网络通信,一共有三种模式:UDP模式、VXLAN模式、HostGateway模式。
- Calico:另一种K8s的网络插件,用于实现跨节点的网络通信,一共有两种模式:BGP模式、IPIP模式。
思路一:路由方案
我只要让每个节点相互“认识”一下就行。
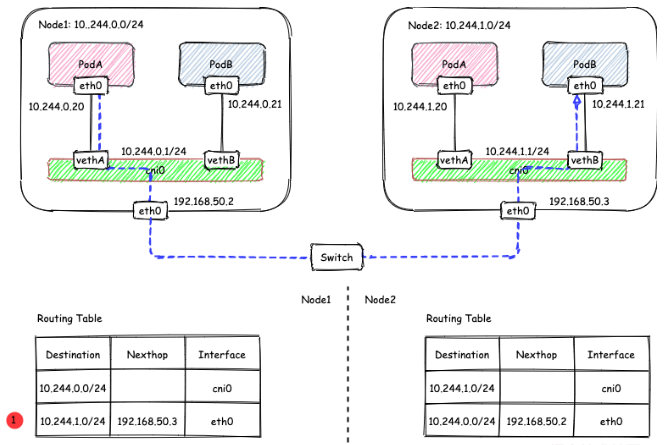
节点1(10.57.4.20)运行着PodA、PodB,节点2(10.57.4.21)运行着PodC、PodD。
当PodA想发送数据给PodC,就在节点1上设置到PodC的路由信息。同理,PodC收到数据后,给PodA回数据,就在节点2上设置到PodA的路由信息。
而且,我们可以针对每个节点,都给这个节点划分唯一的网段,比如说节点1的网段为192.168.11.0/24,节点2的网段192.168.10.0/24(注意:这里的网段是给Pod分配IP用的,不是给节点本身用的),这样有两个好处:
- 集群中所有的Pod的IP地址不会重复,不会冲突,可以减少不必要的麻烦。
- 我们上面所设置的路由,只要针对每个节点所在的网段进行设置就可以了。例如:在节点1上建立一条路由,所有发往192.168.10.0/24(节点2上的Pod)的数据包,都从节点1的物理网卡(eth0)发出,下一跳的地址是10.57.4.21。
这样,只要所有节点都相互设置了对方的Pod网段,当数据包到达目标节点后,就可以让目标节点上的网桥再转发到对应的Pod。
这种方案被称为路由方案。方案的核心,是将节点机器本身作为一个路由转发设备,帮Pod正确地把数据包路由出去。
把Flannel的host-gw模式和Calico的BGP模式就是用的这个方案。
接下来我们分别介绍下这两个模式的具体实现细节。
Flannel的host-gw的模式
我准备了两台节点:
- host1(ip:10.57.4.20)
- host2(ip:10.57.4.21)
host1中创建pod-a(ip:192.168.10.10)
host2上创建pod-b(ip:192.168.11.10)
在这里,我们划分了两个网段:192.168.11.0/24网段和192.168.10.0/24
可以用ip route命令配置主机上的路由表,要让pod-a和pod-b相互通信,只需要在两台主机上加一条路由即可:
- host1:
ip route add 192.168.11.0/24 via 10.57.4.21 dev eth0 onlink # 这个eth0是host1连接host2的网卡,要根据你的测试节点的情况调整
- host2:
ip route add 192.168.10.0/24 via 10.57.4.20 dev eth0 onlink # 这个eth0是host2连接host1的网卡,要根据你的测试节点的情况调整
上面第一条命令的意思是:所有发送到192.168.11.0/24网段的数据包,下一跳的IP地址是10.57.4.21(host2的IP地址),通过节点的eth0(也就是物理网卡)发送出去。
此时在pod-a中去ping pod-b应该是通了的,假设在pod-b的8080端口运行着一个http服务,在pod-a中请求这个服务,在主机路由的模式下,host1发往host2的数据包是长这样的:

注意这里的IP头部,IP是容器的IP,但是MAC地址却是节点的MAC地址。我们知道,数据包发送过程中,除非经过NAT(网络地址映射),否则IP不会变化,始终标识的是通信双方,但是MAC地址是每一段都在变化。数据包从PodA到PodB一共会经历三段变化。我们用图来表示整个网络结构。
- 从pod-a发往host1时,源mac是pod-a的eth0网卡的mac,而目标mac是pod-a的默认网关(169.254.10.24)的mac,因为主机的veth-pod-a开启了arp代答,所以目标mac其实是主机上veth-pod-a的mac地址。
- 从host1去往host2的过程中,所以源MAC是host1的eth0网卡的mac,目标MAC是host2的eth0网卡的mac。
- 从host2发往pod-b,源mac是host2上veth-pod-b网卡的mac,目标mac是pod-b的eth0网卡mac
这是跨节点容器通信方式中最简单高效的方式,没有封包拆包带来的额外消耗。
但是这个方式,也有限制。
限制是:集群每个节点必须在相同网段,因为节点路由的下一跳必须是二层可达的地址。所谓二层可达,就是每一个节点上都保存有下一跳设备的MAC地址。
限制的来源在于,整个通信过程使用的是Pod的IP,并不是节点的IP。我们都知道,在数据链路层,我们使用的是MAC地址进行通信。从host1去往host2的过程中,源MAC是host1的eth0网卡的mac,目标MAC是host2的eth0网卡的mac。这两个host就是二层可达的。
如果不是二层可达的呢?比方说,中间还加了一个三层路由器?
整个过程中始终使用的是Pod的IP,由于 Pod IP 地址在外部网络中通常是不可路由的私有地址,上层路由器通常不会知道如何正确处理这些地址,导致数据包被丢弃。所以,flannel的host-gw方案只能用在同一子网下的多台节点。
Calico的BGP模式
但是,Calico的BGP模式可以不需要同一子网。
BGP允许将Pod的IP地址作为网络层可达信息(NLRI)通过路由协议传播到数据中心内的路由器和其他网络设备,使得这些设备能够知道如何将流量导向拥有这些Pod IP地址的节点。BGP是一种广泛应用于大规模网络环境中的路由协议,尤其在互联网服务提供商(ISP)、数据中心互联(DCI)以及多区域网络中扮演关键角色。BGP允许路由器之间交换路由信息,构建全局可达性视图。
仅需数据中心内部的节点(如Kubernetes集群节点)上的BGP代理(如Calico使用BIRD)与数据中心的边缘路由器建立BGP会话,将Pod网络的路由信息发布出去即可。这种配置并不局限于IDC机房,也适用于企业私有云、混合云等多种环境。虽然BGP配置相对复杂,但其强大的策略控制能力和对大规模网络的支持使其在许多场景下具有吸引力。
在Calico BGP模式下,路由器中存储的是Pod的IP地址及其关联的下一跳(Next Hop)信息,通常是承载该Pod的节点的IP地址。BGP是一个网络层(Layer 3)协议,它关注的是IP路由而非数据链路层(Layer 2)的细节。Pod被视为网络中的逻辑主机,其IP地址如同任何其他网络设备的IP地址一样,被路由器用于路由决策。
因此,BGP模式可以运行在三层网络上。属于纯三层的网络方案,同时也属于覆盖网络的一种。所谓覆盖网络,就是在已有物理网络设施的基础上构建的逻辑网络。
思路二:封包方案
既然上面的思路,使用的是Pod的IP,要保证链路上的设备要认识PodIP,才能正确的转发。
那么这次,我们不用Pod的IP,直接用Pod所在节点的信息进行封装,冒充是节点之间的通信,让Pod的数据包搭上节点通信的顺风车,到了目的地之后,在进行解包分发处理。
这样,对于节点之间的网络就不需要改造了,直接利用现成的网络就行。
Flannel的VXLAN模式
主机路由是按普通路由器的工作原理,每一跳修改MAC地址。
vxlan模式则是把pod的数据帧(注意这里是帧,就是包含二层帧头)封装在主机的UDP包的payload中,数据包封装的工作由linux虚拟网络设备vxlan完成。
vxlan设备在封包时是根据目标MAC地址来决定外层包的目标IP,所以需要主机提供目标MAC地址与所属节点IP的映射关系,这些映射关系存在主机的fdb表(forwarding database)中,fdb记录可以用下面的命令查看:
bridge fdb show|grep vxlan0
8a:e7:df:c0:84:07 dev vxlan0 dst 10.57.4.21 self permanent
上面的记录的意思是说去往MAC地址为8a:e7:df:c0:84:07的pod在节点IP为10.57.4.21的节点上,fdb的信息可以手工维护,也可以让vxlan设备自动学习;
- 手工添加一条fdb记录的命令如下:
bridge fdb append 8a:e7:df:c0:84:07 dev vxlan0 dst 10.57.4.21 self permanent
然后 host1:
ip link add vxlan0 type vxlan id 100 dstport 4789 local 10.57.4.20 dev eth0 learning ## 这个eth0要根据你自己测试节点的网卡调整
ip addr add 192.168.10.1/32 dev vxlan0
ip link set vxlan0 up
ip route add 192.168.11.0/24 via 192.168.11.1 dev vxlan0 onlink
bridge fdb append 00:00:00:00:00:00 dev vxlan0 dst 10.57.4.21 self permanent
host2:
ip link add vxlan0 type vxlan id 100 dstport 4789 local 10.57.4.21 dev eth0 learning ## 这个eth0要根据你自己测试节点的网卡调整
ip addr add 192.168.11.1/32 dev vxlan0
ip link set vxlan0 up
ip route add 192.168.10.0/24 via 192.168.10.1 dev vxlan0 onlink
bridge fdb append 00:00:00:00:00:00 dev vxlan0 dst 10.57.4.20 self permanent
此时pod-a请求pod-b的http服务,数据包从host-1发往host-2时是长这样的:

可以看到,vxlan包是把整个pod-a发往pod-b最原始的帧都装进了一个udp数据包的payload中,整个流程简述如下:
- 1、pod-a数据包到达host-1,源ip为pod-a,目标ip为pod-b,源mac为pod-a,目标mac为host-1中的veth-pod-a
- 2、主机因为开启了转发,所以查找路由表中去往pod-b的下一跳,查到匹配的路由信息如下:
192.168.11.0/24 via 192.168.11.1 dev vxlan0 onlink
## 这是我们在上面的host1执行的命令中的第四条命令添加的
- 3、于是主机把数据包给了vxlan0,并且下一跳为192.168.11.1,此时vxlan0需要得到192.168.11.1的mac地址,但主机的邻居表中不存在,于是vxlan0发起arp广播去询问,vxlan0的广播范围是由我们配置的,这个范围就是我们给他加的全0 fdb记录标识的dstIP,就是上面命令中的:
bridge fdb append 00:00:00:00:00:00 dev vxlan0 dst 10.57.4.21 self permanent
所以,这里找到的目标只有一个,就是10.57.4.21,然后vxlan就借助host1的eth0发起了这个广播,只不过eth0发起的不是广播,而是有明确目标IP的udp数据包,如果上面我们是配置了多个全0的fdb记录,这里eth0就会发起多播。
- 4、192.168.11.1这个地址是我们配置在host2上的vxlan0的网卡地址,于是host2会响应arp请求,host1的vxlan设备得到192.168.11.1的mac地址后,vxlan会从主机的fdb表中查找该mac的下一跳的主机号,发现找不到,于是又发起学习,问谁拥有这个mac,host-2再次应答,于是vxlan0就拥有了封包需要的全部信息,于是把包封装成图三的样子,扔给了host1的eth0网卡;
- 5、host2收到这个包后,因为是一个普通的udp包,于是一直上送到传输层,传输层对于这个端口会有个特殊处理,这个特殊处理会把udp包里payload的信息抠出来扔给协议栈,重新走一遍收包流程。
vxlan学习fdb的方式难免会在主机网络间产生广播风暴,所以flannel的vxlan模式下,是关闭了vxlan设备的learning机制,然后用控制器维护fdb记录和邻居表记录的
从上面的过程可以看出来,vxlan模式依赖udp协议和默认的4789端口,所以在云平台的ECS上使用vxlan模式,还是需要在安全组上把udp 4789端口放开
Calico的ipip模式
ipip模式也是采用封包的方案,是calico的默认方案。
ipip模式是给需要转发的数据包前面加一层IP包,然后链路层是以外层ip包的目标地址封装以太网帧头,而原来的那层ip包更像是被当成了外层包的数据,完成这个封包过程的是linux 虚拟网络设备tunnel网卡,它的工作原理是用节点路由表中匹配原ip包的路由信息中的下一跳地址为外层IP包的目标地址,以本节点的IP地址为源地址,再加一层IP包头,所以使用ip tunnel的模式下,我们需要做两件事情:
- 在各个主机上建立一个one-to-many的ip tunnel,(所谓的one-to-many,就是创建ip tunnel设备时,不指定remote address,这样一个节点只需要一张tunnel网卡)
- 维护节点的路由信息,目标地址为集群的每一个的node-cidr,下一跳为node-cidr所在节点的IP,跟上面的主机路由很像,只不过出口网卡就不再是eth0了,而是新建的ip tunnel设备;
在两台主机上分别创建ip tunnel设备
host1:
ip tunnel add mustang.tun0 mode ipip local 10.57.4.20 ttl 64
ip link set mustang.tun0 mtu 1480 ##因为多一层IP头,占了20个字节,所以MTU也要相应地调整
ip link set mustang.tun0 up
ip route add 192.168.11.0/24 via 10.57.4.21 dev mustang.tun0 onlink
ip addr add 192.168.10.1/32 dev mustang.tun0 ## 这个地址是给主机请求跨节点的pod时使用的
host2:
ip tunnel add mustang.tun0 mode ipip local 10.57.4.21 ttl 64
ip link set mustang.tun0 mtu 1480
ip link set mustang.tun0 up
ip route add 192.168.10.0/24 via 10.57.4.20 dev mustang.tun0 onlink
ip addr add 192.168.11.1/32 dev mustang.tun0
这时候两个pod应该已经可以相互ping通了,还是假设pod-a请求pod-b的http服务,此时host1发往host2的数据包是长这样的:

因为主机协议栈工作时是由下往上识别每一层包,所以ipip包对于主机协议栈而言,与正常主机间通信的包并没有什么不同,帧头中的源/目标mac是主机的,ip包头中源/目标ip也是节点的,这让节点所处的物理网络也感觉这是正常的节点流量,所以 这个模式相对于主机路由来说对环境的适应性更广,起码跨网段的节点也是可以通的,但是在云平台上使用这种模式还是要注意下,留意图二中外层IP包中的传输层协议号是不一样的(是IPPROTO_IPIP),正常的IP包头,这应该是TCP/UDP/ICMP,这样有可能也会被云平台的安全组策略拦截掉,在linux内核源码中可以看到:
//include/uapi/linux/in.h
enum {
...
IPPROTO_ICMP = 1, /* Internet Control Message Protocol */
#define IPPROTO_ICMP IPPROTO_ICMP
IPPROTO_IPIP = 4, /* IPIP tunnels (older KA9Q tunnels use 94) */
#define IPPROTO_IPIP IPPROTO_IPIP
IPPROTO_TCP = 6, /* Transmission Control Protocol */
#define IPPROTO_TCP IPPROTO_TCP
IPPROTO_UDP = 17, /* User Datagram Protocol */
#define IPPROTO_UDP IPPROTO_UDP
...
一般而言我们在云平台安全组设置规则时,传输层协议都只有三个可选项,就是:TCP、UDP、ICMP(没有IPIP),所以最好是在云平台上把安全组内的主机间的所有协议都放开,会不会真的被拦截掉要看具体云平台,华为云是会限制的;
笔者曾经试过在华为云上使用ipip模式,总会出现pod-a ping不通ping-b,卡着的时候,在pod-b上ping pod-a,然后两边就同时通了,这是典型的有状态防火墙的现象; 之后我们把集群节点都加入一个安全组,在安全组的规则配置中,把组内所有节点的所有端口所有协议都放开后,问题消失,说明默认对IPIP协议是没有放开的
在host1中执行:
ip netns exec pod-a ping -c 5 192.168.11.10
在host2的eth0用tcpdump打印一下流量,就能看到有两层ip头:
tcpdump -n -i eth0|grep 192.168.11.10
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on eth0, link-type EN10MB (Ethernet), capture size 262144 bytes
18:03:35.048106 IP 10.57.4.20 > 10.57.4.21: IP 192.168.10.10 > 192.168.11.10: ICMP echo request, id 3205, seq 1, length 64 (ipip-proto-4)
18:03:35.049483 IP 10.57.4.21 > 10.57.4.20: IP 192.168.11.10 > 192.168.10.10: ICMP echo reply, id 3205, seq 1, length 64 (ipip-proto-4)
18:03:36.049147 IP 10.57.4.20 > 10.57.4.21: IP 192.168.10.10 > 192.168.11.10: ICMP echo request, id 3205, seq 2, length 64 (ipip-proto-4)
18:03:36.049245 IP 10.57.4.21 > 10.57.4.20: IP 192.168.11.10 > 192.168.10.10: ICMP echo reply, id 3205, seq 2, length 64 (ipip-proto-4)
calico的ipip模式就是这种,ip tunnel解决了主机路由不能在跨网段中使用的问题,在idc机房部署k8s集群的场景下,会拿host-gw和ipip两种模式混合使用,节点在相同网段则用host-gw,不同网段则用ipip,思路和flannel的directrouting差不多,只不过ipip比vxlan性能要好一些;
ip tunnel仍然有一些小小的限制,像上面说的云平台安全组对协议限制的问题。
总结
网络传输过程
每当linux需要向外发送一个数据包时,总是会执行以下步骤:
- 查找到该数据包的目的地的路由信息,如果是直连路由(不知道什么是直连路由?没关系,后面会解释),则在邻居表中查找该目的地的MAC地址
- 如果非直连路由,则在邻居表中找下一跳的MAC地址
- 如果找不到对应的路由,则报“network is unreachable”
- 如果在邻居表中没有查找到相应的MAC信息,则向外发送ARP请求询问
- 发送出去的数据帧,源MAC地址为发送网卡的MAC地址,目标MAC则是下一跳的MAC,只要不经过NAT,那么源目地IP是全程不会变化的,而MAC地址则每一跳都会变化。